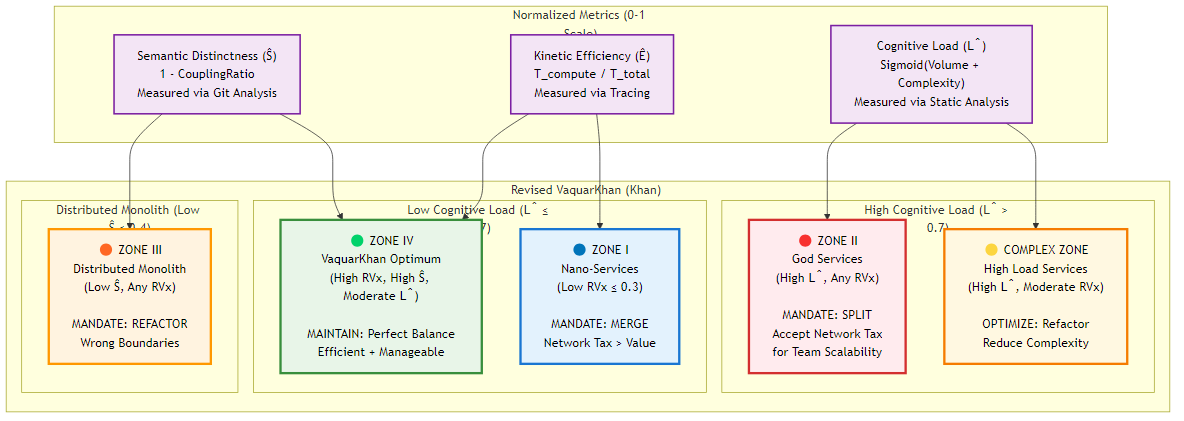
 Figure 8.1: The Khan Granularity Matrix showing the four architectural zones and their corresponding mandates
Figure 8.1: The Khan Granularity Matrix showing the four architectural zones and their corresponding mandatesFocus: Moving bits between services without creating latency storms.
In 2026, we’ve moved beyond the rudimentary “microservices versus monolith” debate into an era of protocol specialization.
The network, once treated as a transparent abstraction by optimistic developers, is now understood as the definitive constraint of system performance - a physical reality governed by the speed of light, packet loss, and serialization overhead. This chapter serves not merely as a catalog of options but as an evidence-based field guide for designing the nervous system of the modern distributed enterprise.
The transition from monolithic architecture to distributed systems is fundamentally an exchange of complexity. We trade the cognitive load of a unified codebase for the operational load of a fragmented topology. In doing so, we incur a non-negotiable cost known as the “Distributed System Tax”.
In a monolithic application, a function call is a memory pointer jump executing in nanoseconds. In microservices architecture, that same logical interaction transforms into a remote procedure call (RPC) traversing the network stack, encompassing serialization, packetization, transmission, buffering, and deserialization. This transformation increases latency by orders of magnitude - typically from nanoseconds to milliseconds, a factor of 10³ to 10⁶.
To mitigate this tax, we must reject the “one size fits all” dogma that plagued the early 2020s, where RESTful JSON over HTTP/1.1 was universally applied regardless of the use case. Instead, we embrace a “Trinity” of protocols, each mathematically optimized for a specific domain: REST for the chaotic, unmanaged public edge; gRPC for the high-velocity, deterministic internal mesh; and GraphQL for the flexible, aggregated Backend-for-Frontend (BFF) layer.
Before a single line of interface definition language (IDL) is written, the architect must engage in an economic analysis of computing resources. The decision to define a service boundary—and consequently, the protocol that bridges it—is a calculation of “Kinetic Friction” versus “Cognitive Load”.
The Khan Index (Ψ) serves as the “Check Engine Light” for microservice granularity, providing a quantitative basis for protocol selection. It moves the discussion from subjective preference to objective metric, assessing whether a service boundary contributes to system velocity or merely adds to the “Network Tax”.
Figure 8.1: The Khan Granularity Matrix showing the four architectural zones and their corresponding mandates
The original Khan Index formulation suffered from critical mathematical flaws that have been addressed in the Revised VaquarKhan Index (RVx). These corrections ensure the formula is suitable for automated governance and dashboard implementation.
Dimensional Homogeneity: All variables are normalized to dimensionless ratios (0-1), eliminating unit dependency issues that could make scores incomparable across different measurement contexts.
Singularity Prevention: The epsilon constant (ε = 0.1) prevents division-by-zero scenarios when analyzing trivial services with minimal cognitive load.
Zone Logic Correction: The decision matrix approach resolves the logical inversion where complex services might incorrectly appear as “low risk” due to mathematical artifacts.
Operational Measurability: Each variable is tied to concrete data sources:
This mathematical foundation transforms the Khan Protocol from a conceptual framework into a rigorous engineering standard suitable for industrial application.
1
RVx = (Ê × Ŝ) / (L̂ + ε)
Where all variables are normalized to dimensionless ratios (0 ≤ value ≤ 1):
Ê (Normalized Kinetic Efficiency):
1
Ê = T_compute / (T_compute + T_network + T_serialize + T_mesh)
Measured via distributed tracing (OpenTelemetry). Represents the percentage of transaction time spent on useful computation versus total overhead.
L̂ (Normalized Cognitive Load):
1
L̂ = 1 / (1 + e^(-(w₁·V + w₂·C + w₃·F - Offset)))
Sigmoid function combining Volume (Lines of Code), Complexity (Cyclomatic), and Fan-out (Dependencies) from static analysis tools.
Ŝ (Normalized Semantic Distinctness):
1
Ŝ = 1.0 - CouplingRatio
Where CouplingRatio is the probability that commits to this service require simultaneous commits to other services (Temporal Coupling analysis from Git history).
ε (Epsilon): Stability constant (0.1) preventing singularity for trivial services. The resulting score maps services into the Khan Granularity Matrix via decision zones:
Zone I: The Nano-Swarm (Low RVx ≤ 0.3)
Zone II: The God Service (High L̂ > 0.7, regardless of RVx)
Zone III: The Distributed Monolith (Low Ŝ ≤ 0.4)
Zone IV: The Khan Optimum (High RVx > 0.6, High Ŝ > 0.6, Moderate L̂)
The “Distributed System Tax” is quantified through the Latency Chain Model. In 2026, empirical analysis confirms that deep synchronous chains of microservices are inherently fragile due to variance amplification. The latency of a microservice architecture is defined as:
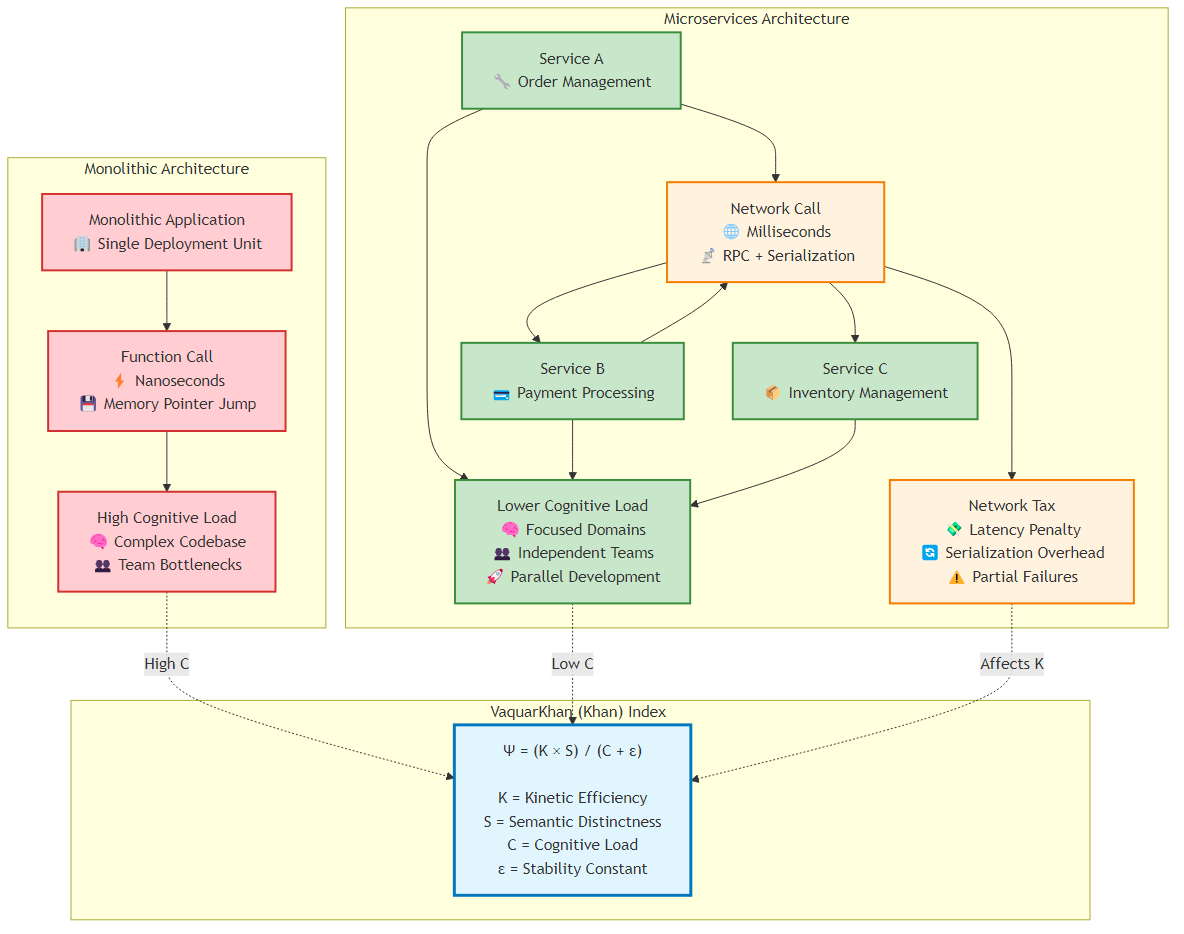 Figure 8.2: Comparison of Network Tax in Monolithic vs Microservices Architecture, illustrating the Khan Index trade-offs
Figure 8.2: Comparison of Network Tax in Monolithic vs Microservices Architecture, illustrating the Khan Index trade-offs
1
L_total = L_compute + L_network + L_serialize + L_mesh
In this equation, L_compute is the only value-adding component (the actual computation). The remaining terms L_network (network transmission), L_serialize (serialization), and L_mesh (service mesh overhead) are pure waste, or “tax,” paid for the privilege of distribution.
Benchmark data from 2026 clearly illustrates the magnitude of this tax:
Throughput Deficit: Monolithic architecture consistently demonstrates approximately 6% higher throughput than their microservice equivalents in concurrency testing due to the absence of this tax.
Variance Amplification: For every synchronous hop added to a request chain, the p99 (tail) latency increases by 15–25%. This non-linear degradation means that a service with a 1% probability of slowness causes a request chain of 100 services to have a 63% probability of being slow.
Infrastructure Overhead: The choice of infrastructure layers exacerbates this tax. For example, benchmarks at 2,000 requests per second (RPS) show that heavy service meshes (like older versions of Istio) can add substantial latency, whereas modern eBPF-based meshes like Cilium add significantly less.
The selection of a protocol from the “Trinity” is essentially an exercise in minimizing specific variables in this equation. REST (using JSON) astronomically increases L_serialize due to textual parsing overhead. gRPC (using Protobuf) minimizes L_serialize and L_network. GraphQL (using aggregations) attempts to reduce the number of hops from the client’s perspective.
Despite the rapid adoption of high-performance alternatives, REST (Representational State Transfer) remains the immutable bedrock of the public internet in 2026. Its dominance is preserved not by raw throughput, but by the “Law of Least Surprise”—its ubiquity, discoverability, and the massive, decentralized infrastructure of the web that supports it.
For the Senior Architect, REST is the default choice for public-facing APIs, B2B integrations, and unknown clients. The strict separation of client and server, enforcing statelessness and standardized HTTP semantics (GET, POST, PUT, DELETE), ensures that any client, from a legacy banking mainframe to a smart toaster, can interact with the system without needing a specialized client library.
The Caching Imperative: REST’s adherence to HTTP semantics unlocks the massive power of the global caching infrastructure. By correctly utilizing headers like ETag, Last-Modified, and Cache-Control, a REST API allows intermediaries—CDNs (Content Delivery Networks), corporate proxies, and browser caches—to serve requests without them ever reaching the origin server. This capability is architecturally unique to REST; gRPC (which uses POST for everything) and GraphQL (which typically uses POST) generally bypass these caching mechanisms, forcing every request to consume backend compute resources. For read-heavy public workloads, this caching capability effectively reduces L_network and L_compute to zero for a significant percentage of traffic.
While REST excels at the edge, it hits a hard “Performance Wall” when applied to high-throughput internal communication (East-West traffic).
Serialization Overhead (L_serialize): JSON (JavaScript Object Notation) is the lingua franca of REST, but it’s computationally expensive. it’s a text-based format that requires the CPU to parse strings, handle whitespace, and convert data types for every message. In microservices with complex object graphs, JSON serialization and deserialization can consume a startling amount of CPU—often exceeding the cost of the actual business logic.
Payload Bloat (L_network): JSON is verbose. It repeats field names for every record in a list (e.g., {"id": 1, "name": "..."}). While GZIP compression helps, it adds yet another CPU cost (L_serialize). In bandwidth-constrained environments, such as poor 4G/EDGE networks, this payload bloat translates directly into increased latency. Pure gRPC payloads are typically 30-50% smaller than their JSON equivalents, offering a massive advantage in throughput.
Strategic Verdict: Use REST for the “Front Door.” it’s the protocol of universal access. don’t use it for the “Kitchen” (internal mesh), where the overhead of text-based conversation creates unacceptable latency storms.
If REST is the public face of the application, gRPC is its internal nervous system. Developed by Google and built on the HTTP/2 standard (and increasingly HTTP/3), gRPC has become the de facto standard for synchronous inter-service communication in 2026 architectures. it’s the technical answer to the “Network Tax,” designed specifically to minimize the latency and bandwidth costs of distribution.
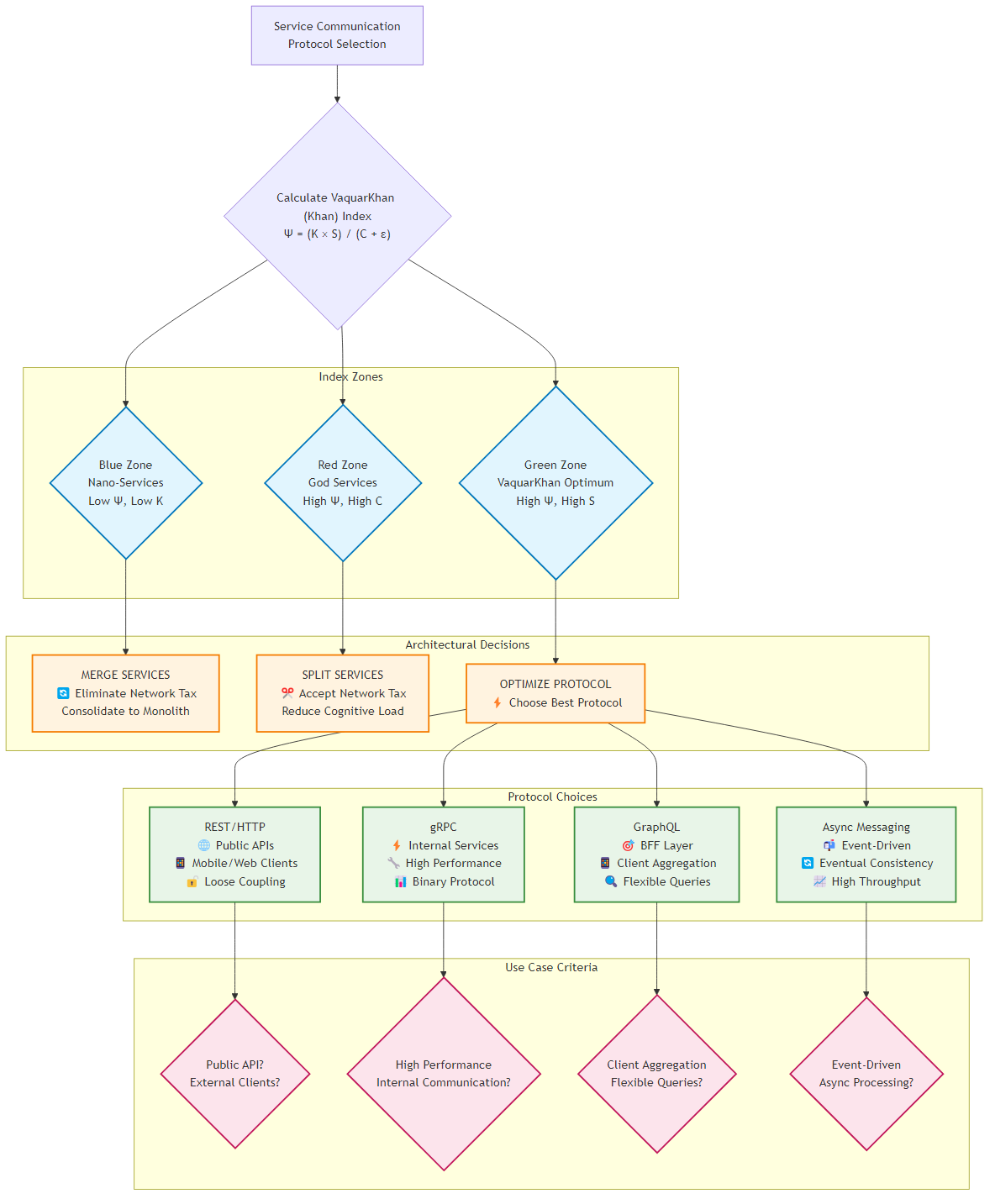 Figure 8.3: Decision tree for protocol selection based on Khan Index analysis and use case requirements
Figure 8.3: Decision tree for protocol selection based on Khan Index analysis and use case requirements
The performance gap between gRPC and REST is not marginal; it’s transformative. Benchmarking data from 2026 consistently demonstrates that gRPC outperforms REST by a factor of 5x to 10x in high-throughput scenarios.
Quantitative Analysis:
In a rigorous benchmark simulating a heavy load (1,000 user threads) with large payloads, the performance disparity becomes stark:
Latency: gRPC maintained an average response time of 6 ms, whereas REST (over HTTP/1.1) suffered an average response time of 552 ms—a difference of nearly two orders of magnitude.
Throughput: Under stress, the REST implementation began to fail, showing a high error rate, while gRPC continued to process requests reliably. The throughput for gRPC in high-performance environments can reach upwards of 50,000 requests per second per node, compared to ~20,000 for optimized REST implementations.
gRPC achieves this performance through three foundational architectural pillars:
Protocol Buffers (Protobuf): Unlike JSON, Protobuf is a binary serialization format. It relies on a strictly typed schema (.proto) known to both client and server. Because the schema is pre-shared, the payload does not need to contain field names, only values. This results in payloads that are drastically smaller than JSON. Furthermore, binary serialization is computationally cheap, reducing the L_serialize component of the latency equation.
HTTP/2 Multiplexing: gRPC utilizes HTTP/2 (and now HTTP/3) to multiplex multiple requests (streams) over a single persistent connection. This eliminates the “connection tax” (the TCP handshake and TLS negotiation overhead) for subsequent requests. HTTP/3 specifically solves the TCP Head-of-Line (HOL) blocking problem, ensuring that packet loss on one stream does not stall the entire connection.
Strict Contracts: The .proto file acts as a canonical contract, enforcing type safety at compile time. This allows for the automatic generation of client stubs in multiple languages (Polyglot support), reducing the cognitive load (L̂) of maintaining client libraries.
gRPC enables communication topologies that are clumsy or impossible to implement efficiently in REST:
Bidirectional Streaming: gRPC allows both clients and server to send a stream of messages independently over the same connection. This is crucial for real-time AI workloads and telemetry feeds.
Flow Control: HTTP/2 provides built-in flow control mechanisms, preventing a fast sender from overwhelming a slow receiver. This resilience is vital for preventing cascading failures in a microservices mesh.
For the Senior Architect, adopting gRPC requires a shift in operational mindset. The persistent nature of connections introduces new challenges in load balancing.
Load Balancing Strategies: Because gRPC connections are persistent, standard Layer 4 load balancers fail to distribute traffic effectively (they balance connections, not requests). Once a client connects to a specific pod, all subsequent requests flow to that same pod, leading to “hot spotting.”
The Solution: You must use Application Load Balancers (ALB) which operate on Layer 7 and natively support gRPC or use client-side load balancing. AWS ALBs in 2026 can inspect individual gRPC streams and route them to different backend targets, ensuring even load distribution.
GraphQL completes the Trinity, serving a highly specialized role: the Backend-for-Frontend (BFF). While gRPC optimizes backend-to-backend traffic, GraphQL optimizes the “Last Mile” between the backend and the client device (mobile, web, IoT).
In a distributed architecture, a single user interface screen often requires data from multiple microservices. In a pure REST environment, the client would have to make three separate network calls. On a high-latency mobile network, this “chattiness” degrades the user experience significantly. GraphQL solves this by inverting the control of data fetching. The client sends a single query specifying exactly the data it needs. The GraphQL server (the aggregator) parses this query, fetches the data from the various underlying microservices (which may speak gRPC or REST), and returns a single, consolidated JSON response. This reduces the network hops seen by the client from N to 1.
Scaling GraphQL across a large organization presents a challenge: how do you manage a single “Supergraph” when dozens of teams own different parts of the data? In 2026, two dominant patterns for “Federation” have emerged.
Comparison of Federation Approaches
| Feature | AWS AppSync Merged APIs | GraphQL Fusion |
|---|---|---|
| Composition Model | Build-Time: Schemas are merged during deployment | Runtime/Build-Time Hybrid: Supports decentralized composition |
| Flexibility | Moderate: Best for AWS-native subgraphs | High: Supports heterogeneous backends (REST, gRPC, GraphQL) via Fusion spec |
| Vendor Lock-in | High: Tightly coupled to AWS ecosystem | Low: Open standard supported by the community and multiple vendors |
| Best For | Teams deeply integrated into AWS seeking managed simplicity | Teams need to aggregate diverse, polyglot legacy services |
Khan Mandate: The Khan Protocol recommends GraphQL Fusion for complex, polyglot environments to ensure high Semantic Distinctness (Ŝ) while avoiding the vendor lock-in of proprietary federation solutions.
GraphQL introduces unique security vectors. The power given to the client to define queries allows malicious actors to craft “Query Depth Attacks”—deeply nested queries that exhaust server resources.
Architectural Defense: Implement strict rate limiting based on Query Complexity scores rather than just request counts. Each field is assigned a cost, and queries exceeding a total cost threshold are rejected.
“Recipe 8.1” in the Field Guide is not merely a code snippet; it’s a scientific methodology for validating protocol decisions. In 2026, the standard toolchain for high-throughput benchmarking is k6 (for scripting flexibility) and ghz (for specialized gRPC load testing).
k6: A modern, developer-centric load testing tool written in Go. It supports both REST and gRPC (via the k6/net/grpc module), allowing for side-by-side comparison. Its ability to simulate “Open Models” makes it superior to older tools like Locust for high-concurrency testing.
ghz: A specialized tool for gRPC benchmarking. it’s preferred for “pure” gRPC tests as it supports binary payloads and custom metadata more natively than generalist tools.
A critical error in benchmarking is using a “Closed Model” (fixed number of users) to test throughput. In a Closed Model, if the system slows down, the load generator inherently slows down because virtual users wait for a response before sending the next request. This masks latency storms.
Recipe 8.1 Mandate: Use the Open Model via the Constant Arrival Rate executor in k6. This simulates a realistic production environment where new requests arrive at a fixed rate (e.g., 2,000 req/sec) regardless of whether the server has finished processing previous requests. This mercilessly exposes queuing bottlenecks.
As we look toward the latter half of the decade, the networking layer itself is evolving to support the Trinity of Protocols with greater efficiency.
The traditional Kubernetes networking model (using kube-proxy and iptables) introduces significant overhead. In 2026, eBPF (Extended Berkeley Packet Filter) has emerged as the standard for high-performance networking.
The Cilium Advantage: Tools like Cilium leverage eBPF to bypass the host networking stack. Cilium can intercept traffic at the socket level, routing it directly to the destination pod without traversing the full TCP/IP stack. This results in significant improvements in throughput and latency compared to standard iptables routing.
Sidecar-less Mesh: eBPF allows Layer 7 observability directly in the kernel. This eliminates the need for resource-heavy sidecar proxies (like Envoy) in every pod, effectively removing the L_mesh term from the latency equation.
HTTP/3 (QUIC) represents the next frontier. While HTTP/2 solved application-layer blocking, it’s still bound by TCP Head-of-Line blocking. HTTP/3 runs over UDP, ensuring that packet loss in one stream does not affect others.
Status in 2026: Support for gRPC over HTTP/3 is becoming widespread at the edge (CloudFront, CDNs). it’s the “End Game” for mobile performance, offering gRPC’s efficiency with QUIC’s resilience on unreliable networks (e.g., switching from Wi-Fi to 5G).
The role of the Senior Architect is not to declare a winner in the “Protocol Wars,” but to orchestrate the Trinity into a coherent system that respects the physics of the network.
Govern with Math: Apply the Revised Khan Index (RVx) to rigorously justify every service boundary. If the score falls into Zone I (The Nano-Swarm), merge the service. If it falls into Zone II (The God Service), split it.
By implementing these protocols with the precision of eBPF networking and the rigor of constant-arrival-rate benchmarking, the architect transforms the “Network Tax” from a crippling liability into a managed operating cost. This is the blueprint for the scalable, resilient systems of the cloud-native era.
As microservices architectures evolve to support AI/ML workloads, a new category of database has emerged as critical infrastructure: Vector Databases. Unlike traditional databases that store and query structured data (rows, columns, documents), vector databases store and query embeddings—high-dimensional numerical representations of semantic meaning.
Why This Matters for Microservices:
The architectural question: Should vector databases be treated as shared infrastructure or as service-specific data stores? The answer, guided by the Adaptive Granularity Strategy, depends on semantic cohesion.
Leading Solutions:
| Database | Type | Strengths | Best For | Pricing Model |
|---|---|---|---|---|
| Pinecone | Managed SaaS | Simplicity, scalability, low latency | Production apps, startups | $0.096/GB/month + queries |
| Weaviate | Open Source / Cloud | GraphQL API, hybrid search, multi-tenancy | Complex schemas, self-hosted | Free (OSS) / Usage-based (Cloud) |
| Milvus | Open Source | High performance, GPU support, Kubernetes-native | Large-scale, on-prem | Free (OSS) / Zilliz Cloud (managed) |
| Qdrant | Open Source / Cloud | Rust-based, filtering, payload storage | High-performance filtering | Free (OSS) / Usage-based (Cloud) |
| pgvector | PostgreSQL Extension | SQL familiarity, ACID transactions | Existing Postgres users | Free (part of Postgres) |
| AWS OpenSearch | Managed Service | AWS integration, k-NN plugin | AWS-native architectures | $0.096/hour (t3.small) |
| Chroma | Open Source | Python-native, simple API | Prototyping, local dev | Free (OSS) |
Pattern 1: Shared Vector Store (Semantic Kernel)
When to Use:
Architecture:
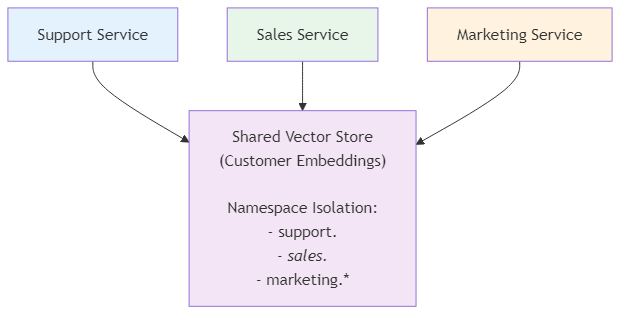 Figure 8.4: Shared vector store architecture with namespace isolation for multiple services accessing common customer embeddings
Figure 8.4: Shared vector store architecture with namespace isolation for multiple services accessing common customer embeddings
Implementation (Pinecone with Namespaces):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
import pinecone
from openai import OpenAI
# Initialize clients
pinecone.init(api_key="YOUR_API_KEY", environment="us-west1-gcp")
openai_client = OpenAI()
# Create index (shared across services)
index_name = "customer-360"
if index_name not in pinecone.list_indexes():
pinecone.create_index(
name=index_name,
dimension=1536, # OpenAI ada-002 embedding size
metric="cosine"
)
index = pinecone.Index(index_name)
# Service-specific namespace usage
class CustomerVectorService:
def __init__(self, service_name: str):
self.service_name = service_name
self.namespace = f"{service_name}_embeddings"
def upsert_customer(self, customer_id: str, customer_data: dict):
"""Store customer embedding in service-specific namespace"""
# Generate embedding
text = f"{customer_data['name']} {customer_data['email']} {customer_data['preferences']}"
embedding = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=text
).data[0].embedding
# Upsert to Pinecone with namespace isolation
index.upsert(
vectors=[(customer_id, embedding, customer_data)],
namespace=self.namespace
)
def semantic_search(self, query: str, top_k: int = 5) -> list:
"""Search within service-specific namespace"""
query_embedding = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=query
).data[0].embedding
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=self.namespace,
include_metadata=True
)
return results['matches']
# Usage by different services
support_service = CustomerVectorService("support")
support_service.upsert_customer("cust_123", {
"name": "John Doe",
"email": "john@example.com",
"preferences": "prefers email, interested in premium features"
})
# Support can only search their namespace
results = support_service.semantic_search("customers interested in upgrades")
Governance:
Pattern 2: Service-Owned Vector Stores
When to Use:
Architecture:
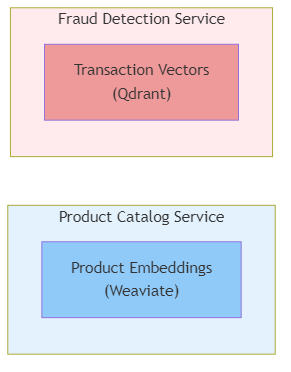 Figure 8.5: Isolated vector stores pattern showing separate databases for distinct semantic domains (Product Catalog vs Fraud Detection)
Figure 8.5: Isolated vector stores pattern showing separate databases for distinct semantic domains (Product Catalog vs Fraud Detection)
Adaptive Granularity Strategy Guidance:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Decision matrix for vector database placement
def should_share_vector_store(service_a: str, service_b: str,
semantic_overlap: float) -> bool:
"""
Determine if two services should share a vector store
Args:
semantic_overlap: 0.0 (no overlap) to 1.0 (complete overlap)
Returns:
True if shared store recommended, False if separate stores
"""
if semantic_overlap > 0.7:
return True # High overlap - share with namespace isolation
elif semantic_overlap > 0.4:
# Medium overlap - consider hybrid approach
# Shared for common entities, separate for service-specific
return "HYBRID"
else:
return False # Low overlap - separate stores
# Example calculations
semantic_overlap_support_sales = 0.8 # Both query customer data
semantic_overlap_product_fraud = 0.1 # Different domains
print(should_share_vector_store("support", "sales",
semantic_overlap_support_sales))
# Output: True
print(should_share_vector_store("product", "fraud",
semantic_overlap_product_fraud))
# Output: False
Pattern: Use vector databases to provide context to LLMs from your microservices data.
Architecture:
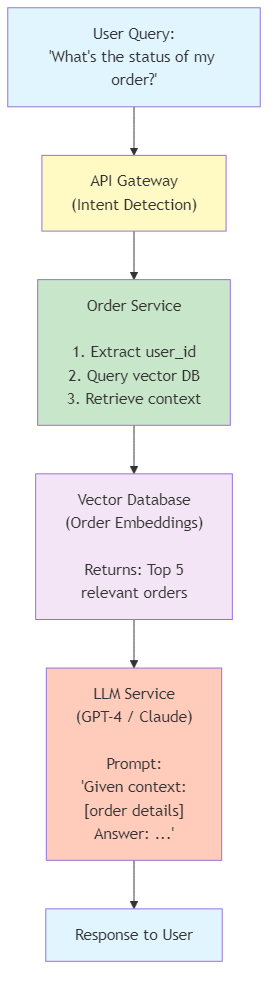 Figure 8.6: Retrieval Augmented Generation (RAG) architecture showing vector database integration with LLM for context-aware responses
Figure 8.6: Retrieval Augmented Generation (RAG) architecture showing vector database integration with LLM for context-aware responses
Implementation:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
from weaviate import Client
from openai import OpenAI
class RAGOrderService:
def __init__(self):
self.weaviate_client = Client("http://localhost:8080")
self.openai_client = OpenAI()
def answer_order_query(self, user_id: str, query: str) -> str:
"""
Use RAG to answer user queries about their orders
"""
# Step 1: Retrieve relevant context from vector DB
context = self._retrieve_context(user_id, query)
# Step 2: Generate answer using LLM with context
answer = self._generate_answer(query, context)
return answer
def _retrieve_context(self, user_id: str, query: str, top_k: int = 5) -> list:
"""Semantic search for relevant orders"""
result = self.weaviate_client.query.get(
"Order",
["order_id", "status", "items", "total", "created_at"]
).with_near_text({
"concepts": [query]
}).with_where({
"path": ["user_id"],
"operator": "Equal",
"valueString": user_id
}).with_limit(top_k).do()
return result['data']['Get']['Order']
def _generate_answer(self, query: str, context: list) -> str:
"""Generate natural language answer using LLM"""
# Format context for LLM
context_str = "\n".join([
f"Order {o['order_id']}: Status={o['status']}, "
f"Total=${o['total']}, Date={o['created_at']}"
for o in context
])
# Create prompt
prompt = f"""You are a helpful customer service assistant.
User Question: {query}
Relevant Order Information:
{context_str}
Instructions:
- Answer the user's question based ONLY on the provided order information
- Be concise and friendly
- If the information isn't in the context, say "I don't have that information"
- don't make up order details
Answer:"""
response = self.openai_client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.3 # Low temperature for factual responses
)
return response.choices[0].message.content
# Usage
rag_service = RAGOrderService()
answer = rag_service.answer_order_query(
user_id="user_123",
query="What's the status of my recent order?"
)
print(answer)
# Output: "Your most recent order (#ORD-456) is currently in transit
# and expected to arrive on February 15th."
Challenge: Pure vector search lacks precision for exact matches (e.g., order IDs, SKUs).
Solution: Hybrid search combines semantic similarity with traditional filters.
Implementation (Weaviate Hybrid Search):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
class HybridProductSearch:
def __init__(self, weaviate_client: Client):
self.client = weaviate_client
def search_products(self, query: str, filters: dict = None,
alpha: float = 0.5) -> list:
"""
Hybrid search combining vector similarity and keyword matching
Args:
query: Natural language search query
filters: Traditional filters (price range, category, etc.)
alpha: Balance between vector (0.0) and keyword (1.0) search
0.5 = equal weight
Returns:
List of matching products
"""
search_query = self.client.query.get(
"Product",
["product_id", "name", "description", "price", "category"]
).with_hybrid(
query=query,
alpha=alpha # 0.5 = balanced hybrid search
)
# Add traditional filters
if filters:
where_filter = self._build_where_filter(filters)
search_query = search_query.with_where(where_filter)
results = search_query.with_limit(20).do()
return results['data']['Get']['Product']
def _build_where_filter(self, filters: dict) -> dict:
"""Convert filters to Weaviate where clause"""
conditions = []
if 'min_price' in filters:
conditions.append({
"path": ["price"],
"operator": "GreaterThanEqual",
"valueNumber": filters['min_price']
})
if 'max_price' in filters:
conditions.append({
"path": ["price"],
"operator": "LessThanEqual",
"valueNumber": filters['max_price']
})
if 'category' in filters:
conditions.append({
"path": ["category"],
"operator": "Equal",
"valueString": filters['category']
})
if len(conditions) == 1:
return conditions[0]
else:
return {"operator": "And", "operands": conditions}
# Usage examples
search = HybridProductSearch(weaviate_client)
# Example 1: Pure semantic search (alpha=0.0)
results = search.search_products(
query="comfortable running shoes for marathon training",
alpha=0.0 # Pure vector search
)
# Example 2: Balanced hybrid search with filters
results = search.search_products(
query="wireless headphones with good bass",
filters={"min_price": 50, "max_price": 200, "category": "Electronics"},
alpha=0.5 # Balanced
)
# Example 3: Keyword-focused search (alpha=1.0)
results = search.search_products(
query="SKU-12345", # Exact match needed
alpha=1.0 # Pure keyword search
)
Challenge: SaaS applications need to isolate tenant data in vector databases.
Solution Patterns:
Pattern A: Namespace per Tenant (Pinecone)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class MultiTenantVectorService:
def __init__(self, index_name: str):
self.index = pinecone.Index(index_name)
def upsert_tenant_data(self, tenant_id: str, document_id: str,
embedding: list, metadata: dict):
"""Store data in tenant-specific namespace"""
namespace = f"tenant_{tenant_id}"
self.index.upsert(
vectors=[(document_id, embedding, metadata)],
namespace=namespace
)
def query_tenant_data(self, tenant_id: str, query_vector: list,
top_k: int = 10) -> list:
"""Query only within tenant's namespace"""
namespace = f"tenant_{tenant_id}"
results = self.index.query(
vector=query_vector,
top_k=top_k,
namespace=namespace,
include_metadata=True
)
return results['matches']
Pattern B: Filter-Based Isolation (Weaviate)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class FilterBasedMultiTenancy:
def __init__(self, weaviate_client: Client):
self.client = weaviate_client
def query_with_tenant_filter(self, tenant_id: str, query: str) -> list:
"""Use where filter to enforce tenant isolation"""
results = self.client.query.get(
"Document",
["doc_id", "content", "metadata"]
).with_near_text({
"concepts": [query]
}).with_where({
"path": ["tenant_id"],
"operator": "Equal",
"valueString": tenant_id
}).with_limit(10).do()
return results['data']['Get']['Document']
Security Best Practices:
Indexing Strategies:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Weaviate: Configure HNSW index for optimal performance
schema = {
"class": "Product",
"vectorIndexType": "hnsw",
"vectorIndexConfig": {
"ef": 128, # Higher = better recall, slower indexing
"efConstruction": 256, # Higher = better index quality
"maxConnections": 64 # Higher = better recall, more memory
},
"properties": [
{"name": "name", "dataType": ["string"]},
{"name": "description", "dataType": ["text"]},
{"name": "price", "dataType": ["number"]},
]
}
weaviate_client.schema.create_class(schema)
Caching Strategy:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
from functools import lru_cache
import hashlib
class CachedVectorSearch:
def __init__(self, vector_db):
self.vector_db = vector_db
@lru_cache(maxsize=1000)
def search_with_cache(self, query: str, top_k: int = 5) -> tuple:
"""Cache search results for repeated queries"""
# Generate embedding (this is expensive)
embedding = self._generate_embedding(query)
# Search vector DB
results = self.vector_db.query(embedding, top_k=top_k)
# Return as tuple (hashable for caching)
return tuple(results)
def _generate_embedding(self, text: str) -> list:
"""Generate embedding with caching"""
# Hash the text for cache key
text_hash = hashlib.md5(text.encode()).hexdigest()
# Check Redis cache first
cached = redis_client.get(f"embedding:{text_hash}")
if cached:
return json.loads(cached)
# Generate new embedding
embedding = openai_client.embeddings.create(
model="text-embedding-ada-002",
input=text
).data[0].embedding
# Cache for 24 hours
redis_client.setex(
f"embedding:{text_hash}",
86400,
json.dumps(embedding)
)
return embedding
Vector Database Cost Comparison (Monthly, 1M vectors, 1536 dimensions):
| Solution | Storage Cost | Query Cost | Total (Est.) |
|---|---|---|---|
| Pinecone | ~$96/month | $0.40/1M queries | $136/month (10M queries) |
| Weaviate Cloud | ~$80/month | Included | $80/month |
| Self-Hosted Milvus | $50 (EC2) | $0 | $50/month |
| pgvector (RDS) | $30 (db.t3.medium) | $0 | $30/month |
Cost Optimization Strategies:
pca = PCA(n_components=768) reduced_embeddings = pca.fit_transform(original_embeddings)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2. **Quantization:**
```python
# Use int8 quantization instead of float32 (75% storage savings)
import numpy as np
def quantize_embedding(embedding: list) -> bytes:
"""Convert float32 to int8"""
arr = np.array(embedding, dtype=np.float32)
# Normalize to [-1, 1]
normalized = arr / np.linalg.norm(arr)
# Scale to int8 range
quantized = (normalized * 127).astype(np.int8)
return quantized.tobytes()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# Hot data in Pinecone, cold data in S3
class TieredVectorStorage:
def __init__(self):
self.hot_store = pinecone.Index("hot-vectors")
self.s3_client = boto3.client('s3')
def archive_old_vectors(self, cutoff_date: datetime):
"""Move old vectors to S3"""
# Query old vectors
old_vectors = self.hot_store.query(
filter={"created_at": {"$lt": cutoff_date.isoformat()}}
)
# Save to S3
self.s3_client.put_object(
Bucket='vector-archive',
Key=f'archive-{cutoff_date.isoformat()}.json',
Body=json.dumps(old_vectors)
)
# Delete from hot store
self.hot_store.delete(ids=[v['id'] for v in old_vectors])
Key Metrics:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# CloudWatch metrics for vector database operations
def publish_vector_db_metrics(operation: str, latency_ms: float,
result_count: int, cost_usd: float):
cloudwatch.put_metric_data(
Namespace='VectorDatabase',
MetricData=[
{
'MetricName': 'QueryLatency',
'Value': latency_ms,
'Unit': 'Milliseconds',
'Dimensions': [
{'Name': 'Operation', 'Value': operation},
{'Name': 'Database', 'Value': 'Pinecone'}
]
},
{
'MetricName': 'ResultCount',
'Value': result_count,
'Unit': 'Count'
},
{
'MetricName': 'QueryCost',
'Value': cost_usd,
'Unit': 'None'
}
]
)
This chapter explored the Trinity of Protocols in microservices architecture, providing comprehensive insights into REST, gRPC, and GraphQL selection based on the Khan Index, performance benchmarking, and advanced networking trends. We also covered the emerging critical infrastructure of vector databases for semantic search, RAG architectures, and AI-native microservices.
In the next chapter, we’ll continue our journey through microservices architecture.
Navigation: