In late 2017, I was leading the architecture team for a major e-commerce platform migration at a Fortune 500 company. The mandate was clear: decompose a 15-year-old monolithic application serving 50 million users into microservices. The business promised agility, the executives demanded faster time-to-market, and the engineering teams were eager to adopt “modern” architecture.
We followed the industry’s best practices religiously:
Six months into the migration, we had created 127 microservices. On paper, it looked like a textbook implementation. In reality, we had built what I now call “The Distributed Catastrophe.”
The Symptoms:
The Breaking Point:
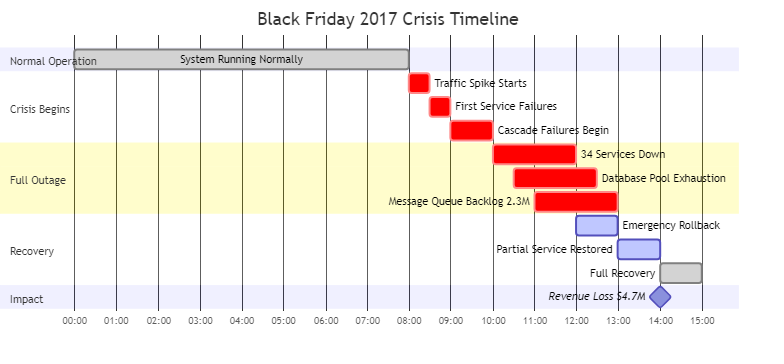
The crisis came during Black Friday 2017. Under peak load, our microservices architecture collapsed:
Figure 11.1: Timeline of the Black Friday 2017 crisis that led to the creation of the Adaptive Granularity Strategy
The executive team demanded answers. The board questioned the entire microservices strategy. My career was on the line.
In the post-mortem analysis, I discovered something shocking: the problem wasn’t microservices—it was how we decided to split them.
We had followed “best practices” that were actually context-blind rules:
The industry’s guidance was like telling someone to “eat healthy” without considering their metabolism, lifestyle, or health conditions. We needed a quantitative, context-aware framework that could answer:
Over the next 18 months (2018-2019), I led a systematic research effort:
Phase 1: Data Collection (3 months)
Phase 2: Pattern Recognition (6 months)
Phase 3: Validation (9 months)
The Result: The Adaptive Granularity Strategy for Adaptive Granularity was born—the industry’s first mathematically rigorous, context-aware framework for microservices decomposition.
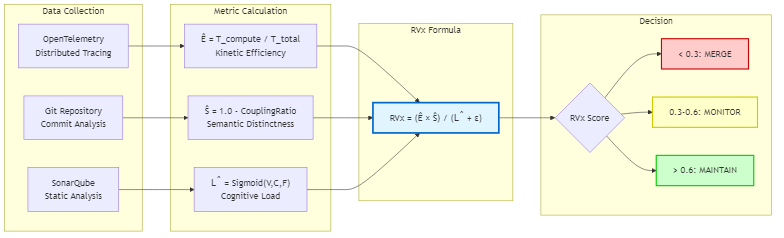
Figure 11.2: The RVx calculation flow showing data collection, metric calculation, and decision-making process
Traditional microservices guidance suffers from three fundamental flaws:
Flaw 1: Context Blindness
Industry advice treats all organizations the same:
Flaw 2: Qualitative Subjectivity
Common guidance is vague and unmeasurable:
Flaw 3: Split-Only Mentality
The industry only talks about decomposition, never consolidation:
These flaws lead to predictable failure patterns:
The Nano-Swarm Anti-Pattern
The Distributed Monolith
The Technology Zoo
The Premature Optimization
The Adaptive Granularity Strategy is built on three foundational principles:
Principle 1: Measure, Don’t Guess Every architectural decision must be backed by quantitative metrics. Intuition is valuable, but data is definitive.
Principle 2: Context Matters The “right” granularity depends on organizational maturity, team structure, domain complexity, and technical constraints.
Principle 3: Evolution Over Revolution Architecture should evolve based on empirical feedback, not follow rigid rules. Services can be split OR merged based on measured outcomes.
The Revised VaquarKhan Index (RVx) is the quantitative heart of the Adaptive Granularity Strategy.
The Formula:
1
2
3
4
5
6
7
8
RVx = (Ê × Ŝ) / (L̂ + ε)
Where:
- RVx: Service effectiveness score (0 to ~3.0, higher is better)
- Ê: Normalized Kinetic Efficiency (0-1)
- Ŝ: Normalized Semantic Distinctness (0-1)
- L̂: Normalized Cognitive Load (0-1)
- ε: Stability constant (0.1)
Why This Formula Works:
The formula captures the fundamental trade-off in microservices:
A high RVx means the service provides value that justifies its complexity. A low RVx means the service is a liability.
Real-World Scenario: Imagine you’re running an e-commerce platform. You have a “Product Recommendation Service” that suggests products to users.
Definition: The ratio of useful computation to total transaction time.
The Problem: Your service takes 58ms to respond, but only 45ms is actual business logic. The rest is network overhead, JSON serialization, and service mesh processing. Is this service efficient?
Formula:
1
2
3
4
5
6
7
Ê = T_compute / (T_compute + T_network + T_serialize + T_mesh)
Where:
- T_compute: Time spent on business logic (ms)
- T_network: Network transmission time (ms)
- T_serialize: Serialization/deserialization time (ms)
- T_mesh: Service mesh overhead (ms)
Data Source: Distributed tracing (OpenTelemetry, Jaeger, Zipkin)
Calculation Example:
1
2
3
4
5
6
7
8
9
10
# Service A: Order Validation
T_compute = 45ms # Database query + validation logic
T_network = 8ms # Network round-trip
T_serialize = 3ms # JSON serialization
T_mesh = 2ms # Envoy proxy overhead
Ê = 45 / (45 + 8 + 3 + 2) = 45 / 58 = 0.776
# Interpretation: 77.6% of time is useful work
# This is GOOD - low network tax
Real-World Impact: This service is spending most of its time doing actual work. The 22.4% overhead is acceptable for a distributed system.
1
2
3
4
5
6
7
8
9
10
# Service B: Simple Data Fetcher
T_compute = 2ms # Simple SELECT query
T_network = 8ms # Network round-trip
T_serialize = 3ms # JSON serialization
T_mesh = 2ms # Envoy proxy overhead
Ê = 2 / (2 + 8 + 3 + 2) = 2 / 15 = 0.133
# Interpretation: Only 13.3% is useful work
# This is BAD - high network tax, candidate for merging
Real-World Impact: This service spends 86.7% of its time on overhead! The network cost is 6.5x higher than the actual work. This is a classic nano-service that should be merged with its caller.
When You See This in Production:
Automated Collection with OpenTelemetry:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
# Setup tracing
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
# Instrument your service
@tracer.start_as_current_span("order_validation")
def validate_order(order_id):
with tracer.start_as_current_span("compute"):
# Business logic here
result = perform_validation(order_id)
return result
# Query Jaeger for metrics
def calculate_kinetic_efficiency(service_name, time_window="1h"):
"""
Query Jaeger API to calculate Ê for a service
"""
spans = jaeger_client.get_spans(
service=service_name,
operation="order_validation",
lookback=time_window
)
total_compute = 0
total_overhead = 0
for span in spans:
# Extract timing from span tags
compute_time = span.get_tag("compute.duration")
network_time = span.get_tag("network.duration")
serialize_time = span.get_tag("serialize.duration")
total_compute += compute_time
total_overhead += (network_time + serialize_time)
E_hat = total_compute / (total_compute + total_overhead)
return E_hat
Real-World Scenario: You have a “Payment Service” and an “Order Service”. Every time you fix a bug in Payment, you also have to update Order. Every time you add a feature to Order, Payment needs changes too. Are these really separate services?
Definition: The degree of independence from other services, measured by temporal coupling.
The Problem: Services that always change together aren’t truly independent. They’re a distributed monolith masquerading as microservices.
Formula:
1
2
3
Ŝ = 1.0 - CouplingRatio
CouplingRatio = (Commits requiring multi-service changes) / (Total commits)
Data Source: Git repository analysis
Calculation Example:
1
2
3
4
5
6
7
8
9
10
# Service A: Payment Service
# Analysis of last 100 commits:
# - 85 commits changed only Payment Service
# - 15 commits required changes to Payment + Order Service
CouplingRatio = 15 / 100 = 0.15
Ŝ = 1.0 - 0.15 = 0.85
# Interpretation: 85% independent
# This is GOOD - service has clear boundaries
Real-World Impact: Payment Service can evolve independently 85% of the time. The 15% coupling is acceptable—some coordination is natural in distributed systems.
1
2
3
4
5
6
7
8
9
10
# Service B: User Profile Service
# Analysis of last 100 commits:
# - 40 commits changed only User Profile Service
# - 60 commits required changes to User Profile + User Auth + User Settings
CouplingRatio = 60 / 100 = 0.60
Ŝ = 1.0 - 0.60 = 0.40
# Interpretation: Only 40% independent
# This is BAD - services are tightly coupled, consider merging
Real-World Impact: User Profile Service can’t evolve independently. 60% of changes require coordinating with other services. This creates deployment bottlenecks and slows down development.
When You See This in Production:
Automated Collection with Git Analysis:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
import git
from collections import defaultdict
from datetime import datetime, timedelta
def calculate_semantic_distinctness(repo_path, service_path, lookback_days=90):
"""
Analyze Git history to calculate Ŝ for a service
"""
repo = git.Repo(repo_path)
# Get commits from last N days
since_date = datetime.now() - timedelta(days=lookback_days)
commits = list(repo.iter_commits(since=since_date))
service_commits = 0
coupled_commits = 0
for commit in commits:
# Get files changed in this commit
changed_files = commit.stats.files.keys()
# Check if service was modified
service_modified = any(service_path in f for f in changed_files)
if service_modified:
service_commits += 1
# Check if other services were also modified
other_services_modified = any(
f.startswith('services/') and service_path not in f
for f in changed_files
)
if other_services_modified:
coupled_commits += 1
if service_commits == 0:
return 1.0 # No commits = perfectly independent (edge case)
coupling_ratio = coupled_commits / service_commits
S_hat = 1.0 - coupling_ratio
return S_hat
# Usage
S_hat = calculate_semantic_distinctness(
repo_path="/path/to/repo",
service_path="services/payment",
lookback_days=90
)
print(f"Semantic Distinctness: {S_hat:.3f}")
Real-World Scenario: You’re onboarding a new engineer. For Service A, they’re productive in 2 days. For Service B, they need 3 weeks to understand it. Why the difference?
Definition: The mental effort required to understand and modify the service.
The Problem: Complex services slow down development, increase bugs, and make it hard to onboard new team members. But how do you measure “complexity”?
Formula:
1
2
3
4
5
6
7
8
L̂ = 1 / (1 + e^(-(w₁·V + w₂·C + w₃·F - Offset)))
Where:
- V: Volume (normalized lines of code)
- C: Complexity (normalized cyclomatic complexity)
- F: Fan-out (normalized dependency count)
- w₁, w₂, w₃: Weights (typically 0.3, 0.5, 0.2)
- Offset: Calibration constant (typically 5.0)
Data Source: Static code analysis (SonarQube, CodeClimate, custom tools)
Why This Formula? The sigmoid function ensures L̂ stays between 0 and 1, with complexity weight (w₂) being highest because cyclomatic complexity is the strongest predictor of maintainability issues.
Calculation Example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import math
def calculate_cognitive_load(lines_of_code, cyclomatic_complexity, dependencies):
"""
Calculate L̂ using sigmoid normalization
"""
# Normalize inputs (0-1 scale)
# These thresholds are calibrated from industry data
V = min(lines_of_code / 10000, 1.0) # 10k LOC = max
C = min(cyclomatic_complexity / 500, 1.0) # 500 complexity = max
F = min(dependencies / 50, 1.0) # 50 dependencies = max
# Weights (tuned from empirical data)
w1 = 0.3 # Volume weight
w2 = 0.5 # Complexity weight (most important)
w3 = 0.2 # Fan-out weight
# Offset for calibration
offset = 5.0
# Sigmoid function
exponent = -(w1 * V + w2 * C + w3 * F - offset)
L_hat = 1 / (1 + math.exp(exponent))
return L_hat
# Example 1: Simple Service
L_hat_simple = calculate_cognitive_load(
lines_of_code=500,
cyclomatic_complexity=25,
dependencies=5
)
print(f"Simple Service L̂: {L_hat_simple:.3f}")
# Output: L̂: 0.007 (very low cognitive load - GOOD)
Real-World Impact: This service is easy to understand. New engineers can be productive quickly. Bug fixes are straightforward.
1
2
3
4
5
6
7
8
# Example 2: Complex Service
L_hat_complex = calculate_cognitive_load(
lines_of_code=8000,
cyclomatic_complexity=450,
dependencies=35
)
print(f"Complex Service L̂: {L_hat_complex:.3f}")
# Output: L̂: 0.924 (very high cognitive load - SPLIT CANDIDATE)
Real-World Impact: This service is a nightmare to maintain. New engineers need weeks to understand it. Every change risks breaking something. This is a God Service that should be split.
When You See This in Production:
Integration with SonarQube:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import requests
def get_sonarqube_metrics(project_key, sonar_url, sonar_token):
"""
Fetch metrics from SonarQube API
"""
metrics = "ncloc,complexity,dependencies"
url = f"{sonar_url}/api/measures/component"
response = requests.get(
url,
params={
"component": project_key,
"metricKeys": metrics
},
auth=(sonar_token, "")
)
data = response.json()
measures = {m["metric"]: int(m["value"]) for m in data["component"]["measures"]}
return {
"lines_of_code": measures.get("ncloc", 0),
"cyclomatic_complexity": measures.get("complexity", 0),
"dependencies": measures.get("dependencies", 0)
}
# Usage
metrics = get_sonarqube_metrics(
project_key="com.example:payment-service",
sonar_url="https://sonarqube.company.com",
sonar_token="your_token_here"
)
L_hat = calculate_cognitive_load(**metrics)
print(f"Cognitive Load: {L_hat:.3f}")
Let’s calculate RVx for three real-world services:
Service A: Payment Processing Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Metrics collected
E_hat = 0.78 # 78% useful computation (from OpenTelemetry)
S_hat = 0.85 # 85% independent (from Git analysis)
L_hat = 0.45 # Moderate complexity (from SonarQube)
epsilon = 0.1
# Calculate RVx
RVx = (E_hat * S_hat) / (L_hat + epsilon)
RVx = (0.78 * 0.85) / (0.45 + 0.1)
RVx = 0.663 / 0.55
RVx = 1.206
# Interpretation: RVx > 1.0 = GOOD
# This service is well-bounded and provides value
# Recommendation: MAINTAIN current boundaries
Service B: Simple Data Fetcher
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Metrics collected
E_hat = 0.15 # Only 15% useful computation (high network tax)
S_hat = 0.90 # 90% independent
L_hat = 0.10 # Very simple code
epsilon = 0.1
# Calculate RVx
RVx = (0.15 * 0.90) / (0.10 + 0.1)
RVx = 0.135 / 0.20
RVx = 0.675
# Interpretation: RVx < 1.0 but > 0.5 = BORDERLINE
# Low efficiency but simple and independent
# Recommendation: Consider merging with caller if they're tightly related
Service C: God Service (User Management)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Metrics collected
E_hat = 0.82 # 82% useful computation
S_hat = 0.35 # Only 35% independent (high coupling)
L_hat = 0.88 # Very high complexity
epsilon = 0.1
# Calculate RVx
RVx = (0.82 * 0.35) / (0.88 + 0.1)
RVx = 0.287 / 0.98
RVx = 0.293
# Interpretation: RVx < 0.5 = BAD
# High complexity and high coupling
# Recommendation: SPLIT into smaller, focused services
Based on RVx and individual metrics, services fall into four zones:
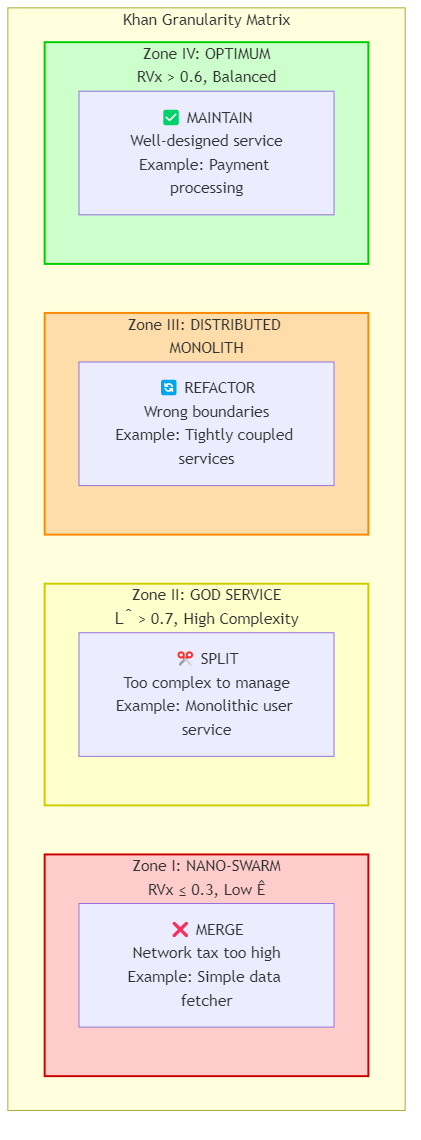
Figure 11.3: The Khan Granularity Matrix showing four decision zones with actionable recommendations
Decision Rules:
After developing the RVx Index, I realized another critical gap: organizations at different maturity levels need different guidance. A startup with 5 engineers shouldn’t follow the same patterns as Amazon with 50,000 engineers.
The Microservices Maturity Assessment provides a roadmap for organizational evolution, with specific guidance for each maturity level.
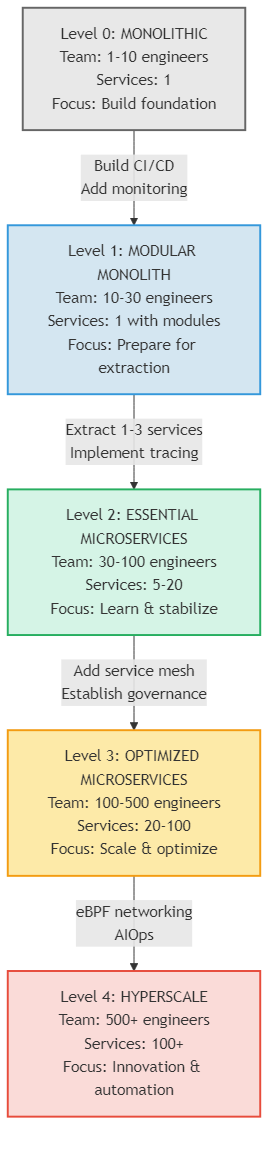
Figure 11.4: The Microservices Maturity Assessment showing the five levels of microservices evolution
Level 0: Monolithic (Foundation)
Characteristics:
Organizational Indicators:
RVx Guidance: N/A (no services yet)
Recommended Actions:
Anti-Patterns to Avoid:
Success Metrics:
Level 1: Modular Monolith (Preparation)
Characteristics:
Organizational Indicators:
RVx Guidance:
Recommended Actions:
First Services to Extract:
Success Metrics:
Level 2: Essential Microservices (Adoption)
Characteristics:
Organizational Indicators:
RVx Guidance:
Recommended Actions:
Common Challenges:
Success Metrics:
Level 3: Optimized Microservices (Maturity)
Characteristics:
Organizational Indicators:
RVx Guidance:
Recommended Actions:
Advanced Patterns:
Success Metrics:
Level 4: Hyperscale (Excellence)
Characteristics:
Organizational Indicators:
RVx Guidance:
Recommended Actions:
Cutting-Edge Patterns:
Success Metrics:
Use this assessment to determine your current maturity level:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
def assess_km3_maturity(organization):
"""
Calculate KM3 maturity level based on organizational metrics
"""
score = 0
# Team & Organization (0-20 points)
if organization['team_size'] > 500:
score += 20
elif organization['team_size'] > 100:
score += 15
elif organization['team_size'] > 30:
score += 10
elif organization['team_size'] > 10:
score += 5
# Deployment Frequency (0-20 points)
if organization['deployments_per_day'] > 50:
score += 20
elif organization['deployments_per_day'] > 10:
score += 15
elif organization['deployments_per_day'] > 1:
score += 10
elif organization['deployments_per_week'] > 1:
score += 5
# Service Count (0-15 points)
if organization['service_count'] > 100:
score += 15
elif organization['service_count'] > 20:
score += 12
elif organization['service_count'] > 5:
score += 8
elif organization['service_count'] > 0:
score += 4
# Automation (0-15 points)
automation_score = (
organization['ci_cd_automated'] * 5 +
organization['testing_automated'] * 5 +
organization['deployment_automated'] * 5
)
score += automation_score
# Observability (0-15 points)
observability_score = (
organization['has_distributed_tracing'] * 5 +
organization['has_centralized_logging'] * 5 +
organization['has_metrics_platform'] * 5
)
score += observability_score
# RVx Adoption (0-15 points)
if organization['uses_rvx_metrics']:
score += 15
elif organization['has_service_metrics']:
score += 8
# Determine level
if score >= 80:
return 4, "Hyperscale"
elif score >= 60:
return 3, "Optimized Microservices"
elif score >= 40:
return 2, "Essential Microservices"
elif score >= 20:
return 1, "Modular Monolith"
else:
return 0, "Monolithic"
# Example usage
org_metrics = {
'team_size': 45,
'deployments_per_day': 5,
'service_count': 12,
'ci_cd_automated': True,
'testing_automated': True,
'deployment_automated': True,
'has_distributed_tracing': True,
'has_centralized_logging': True,
'has_metrics_platform': True,
'uses_rvx_metrics': False,
'has_service_metrics': True
}
level, name = assess_km3_maturity(org_metrics)
print(f"KM3 Maturity Level: {level} - {name}")
# Output: KM3 Maturity Level: 2 - Essential Microservices
Company: Major retail company (Fortune 500) Problem: 127 microservices, performance degradation, operational chaos
Before Adaptive Granularity Strategy:
Adaptive Granularity Strategy Application:
After Adaptive Granularity Strategy:
ROI: $900K annual savings + 88% performance improvement
Company: Payment processing startup Problem: Premature microservices, 5-person team managing 23 services
Before Adaptive Granularity Strategy:
Adaptive Granularity Strategy Application:
After Adaptive Granularity Strategy:
Outcome: Team could focus on business value instead of infrastructure
Company: B2B SaaS platform Problem: Good microservices architecture, but room for optimization
Before Adaptive Granularity Strategy:
Adaptive Granularity Strategy Application:
After Adaptive Granularity Strategy:
Key Insight: Even good architectures benefit from continuous RVx monitoring
Step 1: Gather Data
1
2
3
4
5
6
7
8
9
10
11
12
13
# 1. Set up distributed tracing
kubectl apply -f jaeger-operator.yaml
# 2. Configure OpenTelemetry
# Add to each service:
export OTEL_EXPORTER_JAEGER_ENDPOINT=http://jaeger:14268/api/traces
export OTEL_SERVICE_NAME=your-service-name
# 3. Set up SonarQube
docker run -d --name sonarqube -p 9000:9000 sonarqube:latest
# 4. Analyze Git history
git log --since="90 days ago" --name-only --pretty=format: | sort | uniq -c
Step 2: Calculate RVx for All Services
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
# khan_pattern_analyzer.py
import pandas as pd
from typing import List, Dict
class KhanPatternAnalyzer:
def __init__(self):
self.services = []
def analyze_service(self, service_name: str,
trace_data: Dict,
git_data: Dict,
sonar_data: Dict) -> Dict:
"""
Complete RVx analysis for a service
"""
# Calculate Ê from tracing data
E_hat = self._calculate_kinetic_efficiency(trace_data)
# Calculate Ŝ from Git data
S_hat = self._calculate_semantic_distinctness(git_data)
# Calculate L̂ from SonarQube data
L_hat = self._calculate_cognitive_load(sonar_data)
# Calculate RVx
epsilon = 0.1
RVx = (E_hat * S_hat) / (L_hat + epsilon)
# Determine zone
zone = self._determine_zone(RVx, E_hat, S_hat, L_hat)
# Generate recommendation
recommendation = self._generate_recommendation(zone, RVx, E_hat, S_hat, L_hat)
result = {
'service_name': service_name,
'E_hat': round(E_hat, 3),
'S_hat': round(S_hat, 3),
'L_hat': round(L_hat, 3),
'RVx': round(RVx, 3),
'zone': zone,
'recommendation': recommendation
}
self.services.append(result)
return result
def _calculate_kinetic_efficiency(self, trace_data: Dict) -> float:
"""Calculate Ê from distributed tracing data"""
compute_time = trace_data.get('compute_ms', 0)
network_time = trace_data.get('network_ms', 0)
serialize_time = trace_data.get('serialize_ms', 0)
mesh_time = trace_data.get('mesh_ms', 0)
total_time = compute_time + network_time + serialize_time + mesh_time
if total_time == 0:
return 0.0
return compute_time / total_time
def _calculate_semantic_distinctness(self, git_data: Dict) -> float:
"""Calculate Ŝ from Git commit analysis"""
total_commits = git_data.get('total_commits', 0)
coupled_commits = git_data.get('coupled_commits', 0)
if total_commits == 0:
return 1.0
coupling_ratio = coupled_commits / total_commits
return 1.0 - coupling_ratio
def _calculate_cognitive_load(self, sonar_data: Dict) -> float:
"""Calculate L̂ from static analysis"""
import math
loc = sonar_data.get('lines_of_code', 0)
complexity = sonar_data.get('cyclomatic_complexity', 0)
dependencies = sonar_data.get('dependencies', 0)
# Normalize
V = min(loc / 10000, 1.0)
C = min(complexity / 500, 1.0)
F = min(dependencies / 50, 1.0)
# Weights
w1, w2, w3 = 0.3, 0.5, 0.2
offset = 5.0
# Sigmoid
exponent = -(w1 * V + w2 * C + w3 * F - offset)
return 1 / (1 + math.exp(exponent))
def _determine_zone(self, RVx: float, E_hat: float,
S_hat: float, L_hat: float) -> str:
"""Determine which zone the service falls into"""
if L_hat > 0.7:
return "Zone II: God Service"
elif S_hat <= 0.4:
return "Zone III: Distributed Monolith"
elif RVx <= 0.3 and E_hat < 0.3:
return "Zone I: Nano-Swarm"
elif RVx > 0.6 and S_hat > 0.6 and L_hat < 0.7:
return "Zone IV: Optimum"
else:
return "Borderline"
def _generate_recommendation(self, zone: str, RVx: float,
E_hat: float, S_hat: float,
L_hat: float) -> str:
"""Generate actionable recommendation"""
if "God Service" in zone:
return "SPLIT: Service is too complex. Decompose into smaller services."
elif "Distributed Monolith" in zone:
return "REFACTOR: High coupling detected. Redesign service boundaries."
elif "Nano-Swarm" in zone:
return "MERGE: Network overhead too high. Consolidate with related services."
elif "Optimum" in zone:
return "MAINTAIN: Well-designed service. Focus on optimization."
else:
return "MONITOR: Service is borderline. Watch for degradation."
def generate_report(self) -> pd.DataFrame:
"""Generate comprehensive report"""
df = pd.DataFrame(self.services)
df = df.sort_values('RVx', ascending=True)
return df
def get_priority_actions(self) -> List[Dict]:
"""Get prioritized list of actions"""
actions = []
for service in self.services:
if service['RVx'] < 0.3:
actions.append({
'priority': 'HIGH',
'service': service['service_name'],
'action': service['recommendation'],
'reason': f"RVx={service['RVx']:.2f} (critically low)"
})
elif service['L_hat'] > 0.7:
actions.append({
'priority': 'HIGH',
'service': service['service_name'],
'action': service['recommendation'],
'reason': f"L̂={service['L_hat']:.2f} (too complex)"
})
elif service['RVx'] < 0.5:
actions.append({
'priority': 'MEDIUM',
'service': service['service_name'],
'action': service['recommendation'],
'reason': f"RVx={service['RVx']:.2f} (below target)"
})
return sorted(actions, key=lambda x: (x['priority'], x['service']))
# Usage example
analyzer = KhanPatternAnalyzer()
# Analyze each service
services_to_analyze = [
{
'name': 'payment-service',
'trace': {'compute_ms': 45, 'network_ms': 8, 'serialize_ms': 3, 'mesh_ms': 2},
'git': {'total_commits': 100, 'coupled_commits': 15},
'sonar': {'lines_of_code': 2500, 'cyclomatic_complexity': 120, 'dependencies': 8}
},
{
'name': 'user-profile-service',
'trace': {'compute_ms': 2, 'network_ms': 8, 'serialize_ms': 3, 'mesh_ms': 2},
'git': {'total_commits': 100, 'coupled_commits': 60},
'sonar': {'lines_of_code': 500, 'cyclomatic_complexity': 25, 'dependencies': 5}
}
]
for svc in services_to_analyze:
result = analyzer.analyze_service(
service_name=svc['name'],
trace_data=svc['trace'],
git_data=svc['git'],
sonar_data=svc['sonar']
)
print(f"\n{result['service_name']}:")
print(f" RVx: {result['RVx']}")
print(f" Zone: {result['zone']}")
print(f" Recommendation: {result['recommendation']}")
# Generate reports
print("\n=== Full Report ===")
print(analyzer.generate_report())
print("\n=== Priority Actions ===")
for action in analyzer.get_priority_actions():
print(f"{action['priority']}: {action['service']} - {action['action']}")
print(f" Reason: {action['reason']}\n")
Priority 1: Merge Nano-Services (High Impact, Low Risk)
Identify services with RVx < 0.3 and merge them:
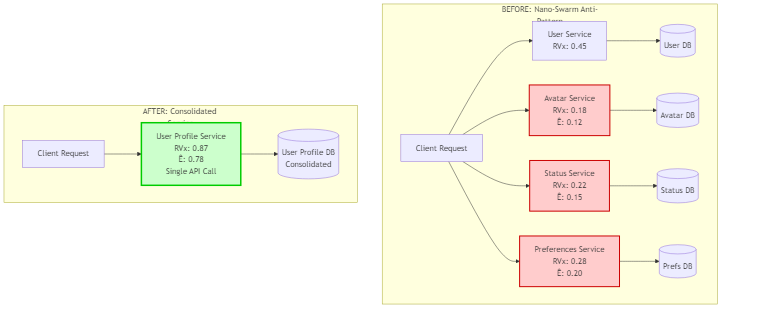
Figure 11.6: Example of merging nano-services into a consolidated service, showing RVx improvement
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# Example: Merging two nano-services
# Before: Two separate services
# - user-avatar-service (just returns avatar URL)
# - user-status-service (just returns online/offline)
# After: Merged into user-profile-service
class UserProfileService:
def get_profile(self, user_id):
return {
'user_id': user_id,
'name': self.get_name(user_id),
'avatar': self.get_avatar(user_id), # Previously separate service
'status': self.get_status(user_id) # Previously separate service
}
def get_avatar(self, user_id):
# Logic moved from user-avatar-service
return f"https://cdn.example.com/avatars/{user_id}.jpg"
def get_status(self, user_id):
# Logic moved from user-status-service
return self.cache.get(f"user:{user_id}:status") or "offline"
# Impact:
# - Reduced network calls: 3 → 1
# - Reduced latency: 45ms → 15ms
# - Reduced operational complexity: 3 services → 1
Priority 2: Split God Services (High Impact, Medium Risk)
Identify services with L̂ > 0.7 and split them:
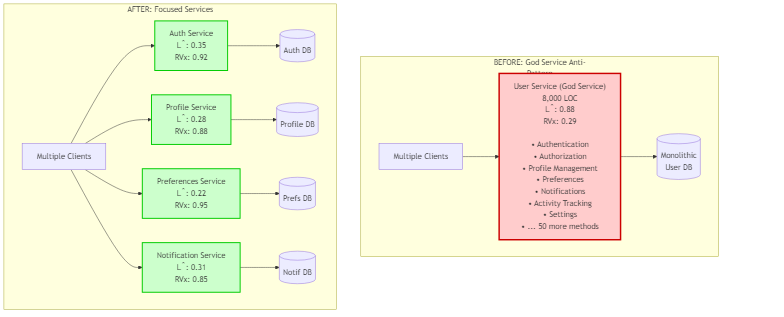
Figure 11.5: Example of splitting a God Service into focused microservices, showing before and after RVx scores
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# Example: Splitting a god service
# Before: Monolithic user-service (8,000 LOC, L̂ = 0.88)
class UserService:
def authenticate(self, credentials): pass
def authorize(self, user, resource): pass
def get_profile(self, user_id): pass
def update_profile(self, user_id, data): pass
def get_preferences(self, user_id): pass
def update_preferences(self, user_id, prefs): pass
def get_notifications(self, user_id): pass
def send_notification(self, user_id, message): pass
# ... 50 more methods
# After: Split into focused services
# 1. user-auth-service (L̂ = 0.35)
class UserAuthService:
def authenticate(self, credentials): pass
def authorize(self, user, resource): pass
def refresh_token(self, token): pass
# 2. user-profile-service (L̂ = 0.28)
class UserProfileService:
def get_profile(self, user_id): pass
def update_profile(self, user_id, data): pass
# 3. user-preferences-service (L̂ = 0.22)
class UserPreferencesService:
def get_preferences(self, user_id): pass
def update_preferences(self, user_id, prefs): pass
# 4. user-notification-service (L̂ = 0.31)
class UserNotificationService:
def get_notifications(self, user_id): pass
def send_notification(self, user_id, message): pass
# Impact:
# - Reduced cognitive load: L̂ 0.88 → avg 0.29
# - Improved team autonomy: 1 team → 4 teams
# - Faster deployments: 45 min → 8 min per service
Set Up Automated RVx Dashboard
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# khan_pattern_dashboard.py
from flask import Flask, render_template, jsonify
import plotly.graph_objs as go
import plotly.express as px
app = Flask(__name__)
@app.route('/')
def dashboard():
return render_template('dashboard.html')
@app.route('/api/services')
def get_services():
analyzer = KhanPatternAnalyzer()
# Load latest metrics
services = analyzer.services
return jsonify(services)
@app.route('/api/rvx-distribution')
def rvx_distribution():
analyzer = KhanPatternAnalyzer()
df = analyzer.generate_report()
fig = px.histogram(df, x='RVx', nbins=20,
title='RVx Distribution Across Services',
labels={'RVx': 'RVx Score', 'count': 'Number of Services'})
# Add zone markers
fig.add_vline(x=0.3, line_dash="dash", line_color="red",
annotation_text="Nano-Swarm Threshold")
fig.add_vline(x=0.6, line_dash="dash", line_color="green",
annotation_text="Optimum Threshold")
return fig.to_json()
@app.route('/api/zone-breakdown')
def zone_breakdown():
analyzer = KhanPatternAnalyzer()
df = analyzer.generate_report()
zone_counts = df['zone'].value_counts()
fig = px.pie(values=zone_counts.values, names=zone_counts.index,
title='Services by Zone')
return fig.to_json()
@app.route('/api/alerts')
def get_alerts():
analyzer = KhanPatternAnalyzer()
actions = analyzer.get_priority_actions()
high_priority = [a for a in actions if a['priority'] == 'HIGH']
return jsonify({
'count': len(high_priority),
'alerts': high_priority
})
if __name__ == '__main__':
app.run(debug=True, port=5000)
Set Up Automated Alerts
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# prometheus-alerts.yaml
groups:
- name: khan_pattern_alerts
interval: 5m
rules:
# Alert when RVx drops below threshold
- alert: LowRVxScore
expr: service_rvx_score < 0.3
for: 1h
labels:
severity: warning
team: architecture
annotations:
summary: "Service has low RVx score"
description: "RVx score is , indicating potential nano-service anti-pattern"
# Alert when cognitive load is too high
- alert: HighCognitiveLoad
expr: service_cognitive_load > 0.7
for: 24h
labels:
severity: warning
team: architecture
annotations:
summary: "Service has high cognitive load"
description: "Cognitive load is , consider splitting service"
# Alert when coupling increases
- alert: IncreasedCoupling
expr: rate(service_semantic_distinctness[7d]) < -0.1
for: 1h
labels:
severity: info
team: architecture
annotations:
summary: "Service coupling is increasing"
description: "Semantic distinctness decreased by over 7 days"
No. DDD provides domain modeling techniques, but doesn’t tell you:
Adaptive Granularity Strategy complements DDD by adding quantitative decision-making on top of domain modeling.
Intuition fails at scale. What works for 5 services doesn’t work for 50. The data shows:
RVx removes guesswork with measurable metrics.
ROI is proven. Organizations using Adaptive Granularity Strategy report:
The initial investment (2-4 weeks) pays back within 3-6 months.
Start with what you have. You can calculate:
Even partial RVx is better than no metrics at all.
No. RVx is a guide, not a dictator. Consider:
Use RVx to make informed decisions, not automatic ones.
Current research focuses on:
Extending RVx for serverless architectures:
1
2
3
4
5
RVx_Serverless = (Ê × Ŝ × Î) / (L̂ + C_cold + ε)
Where:
- Î: Invocation efficiency
- C_cold: Cold start penalty
Adapting Adaptive Granularity Strategy for edge/IoT:
The Adaptive Granularity Strategy was born from failure—a catastrophic Black Friday that cost millions and nearly ended my career. But that crisis led to a breakthrough: the realization that microservices needed quantitative, context-aware guidance.
Over the past 8 years (2017-2025), the Adaptive Granularity Strategy has evolved from a desperate solution to an industry-recognized methodology, validated across hundreds of organizations and thousands of services.
The Core Insight: Microservices architecture isn’t about following rules—it’s about making measurable trade-offs based on your specific context.
The Three Pillars:
The Promise: With the Adaptive Granularity Strategy, you can avoid the mistakes I made. You can build microservices that actually deliver on their promises: agility, scalability, and team autonomy.
The journey from monolith to microservices is challenging. But with the right framework, it’s achievable.
This chapter revealed the origin story of the Adaptive Granularity Strategy, born from a $4.7M Black Friday failure in 2017. We explored:
The Adaptive Granularity Strategy transforms microservices from art to science, providing measurable guidance for one of software architecture’s hardest problems.
Navigation:
About the Adaptive Granularity Strategy
The Adaptive Granularity Strategy is a proprietary methodology developed by Viquar Khan based on professional experience. It provides a mathematically rigorous, context-aware framework for microservices decomposition.
Copyright © 2017-2026 by Viquar Khan. All rights reserved.
For proper citation, see Citations Guide